



採用活動では、応募数、面接数、内定数、内定承諾率、辞退率、採用単価など、さまざまな数字を確認します。しかし、数字を集計するだけでは、どこに課題があり、何を改善すべきかまでは見えてきません。
採用データ分析では、採用プロセスごとの数値を整理し、職種別・チャネル別・時期別・面接官別などの切り口で比較しながら、課題の発生箇所や原因を見立てていきます。重要なのは、単一の指標だけで判断するのではなく、複数のデータを組み合わせて採用活動の状態を読み解くことです。
本記事では、採用活動で見るべき指標や属性、データ分析の基本的な視点、歩留まり分析の進め方、目的別のケーススタディを解説します。
採用活動におけるデータ分析の必要性
近年、採用市場は大きく変化しています。オンライン化の加速、採用チャネルの多様化、人材獲得競争の激化により、これまでの経験だけで良い人材を見極めることがますます難しくなっています。
勘と経験だけの採用が限界を迎えている
そもそも、昔の採用においては「実績があるから大丈夫」「この人は雰囲気が良い」などの経験則や直感で判断していました。しかし、今は以下の理由でその方法が限界を迎えています。
- オンライン選考・スカウト媒体など採用手法の多様化で、どの採用手法が最適か分からない
- 採用担当者ごとに合格基準がバラバラ(再現性がない)
- 早期離職者が増えて、活躍する人材の選び方が分からない
だからこそ、データ分析によって合否判断を可視化し、「勘」ではなく「根拠」で決める採用が求められています。
人材獲得競争の激化と採用難易度の上昇
日本は少子高齢化の影響により労働人口が減少しており、多くの業界で優秀な人材の獲得競争が激化しています。特に新卒採用では年々候補者数が減少しており、「応募が来ない」という課題が顕著に表れています(総務省、労働力調査)。
その結果、企業が求人を出しても母集団が形成できず、採用計画の遅延や採用単価の上昇につながるケースが増えています。こうした状況だからこそ、限られたリソースをデータ分析で最適化し、戦略的に採用を進める必要があります。
採用活動のデータ分析をすることのメリット
“You can’t manage what you don’t measure.”「測定しないものは、マネジメントできない。」
PDCAの生みの親デミングの言葉の通り、採用も感覚では限界があります。データを収集し分析することで、以下のメリットがあります。
採用ROI(費用対効果)の向上とコストの最適化
採用活動には、求人広告費、人材紹介手数料、スカウト媒体の利用料、選考工数など多くのコストが発生します。データ分析を行うことで、効率の高い媒体を見出し、費用対効果(ROI)を明確に把握できます。例えば、媒体ごとの応募数・書類通過率・内定率・入社率を比較すれば「高コストだが内定率が高い媒体」や「応募は多いが採用につながらない媒体」を識別可能です。さらに、スカウト返信率や選考辞退率などのデータも分析すれば、より精度の高いアプローチやフォロー体制の改善につなげることができます。
再現性のある採用ノウハウの蓄積
採用は担当者によって結果が左右されやすい属人的な領域です。しかし、データ分析を活用すれば、成功パターンを定量的に把握し再現性を高めることができます。
- より返信率の高いスカウト文面とは
- より選考辞退率が低くなる選考フローとは
- 入社後活躍した候補者の特徴とは(性格、志向、価値観など)
などを定量的に分析することで、「うまくいった理由」を可視化できます。得られたノウハウをチーム全体で共有・活用することで、組織として安定した採用体制を構築できるでしょう。
選考プロセスの効率化とスピードアップ
応募者の立場では、選考が長引くと「自分の評価が低いのでは」「社内の連携がスムーズでない会社なのでは」と不安になり、選考意欲が徐々に薄れてしまいます。そのため、選考スピードは採用の成功において重要な要素の一つです。データ分析を活用して選考フローのボトルネックを特定・リードタイムを短縮することで、優秀人材の取りこぼしを防ぐことができます。
採用後の定着率の改善
採用の最終ゴールは「採ること」ではなく「定着・活躍させること」です。入社後の活躍・離職傾向と採用時データの関係を分析することで、「入社後に定着・活躍する人材」を採用する精度を高めることができます。さらに、オンボーディング施策や1on1などの人材育成データと組み合わせることで、採用から育成・定着までの一貫したマネジメントが実現します。
採用活動のデータ分析で見るべき指標と属性一覧
採用におけるデータ分析では、特定の指標だけを見るのではなく、採用プロセスごとの数値と、候補者・職種・チャネルなどの属性情報を組み合わせて確認します。たとえば、応募数だけを見るのではなく、応募後の選考参加率や面接通過率、内定承諾率まであわせて見ることで、母集団形成に課題があるのか、選考中の離脱に課題があるのかを切り分けやすくなります。
ここでは、採用活動を分析する際に確認しておきたい代表的な指標と、分析の切り口となる属性を整理します。すべてをKPIとして管理する必要はありませんが、課題の発生箇所や原因を見立てるための材料として把握しておくとよいでしょう。
どの指標をKPIとして設定するかについては、採用KPIの設計方法で詳しく解説しています。
母集団形成(選考前)に関する指標
初回接触に至るまでの流れは、利用する経路によって異なりますが、一般的には以下のようなステップで進みます。
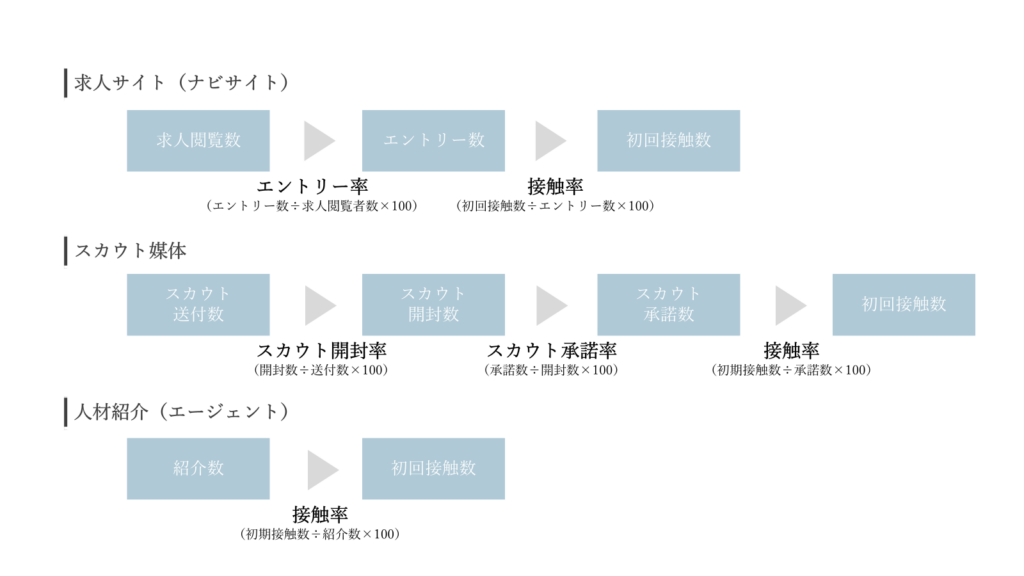
各ステップで候補者が次の段階へどれだけ進んだかを示す指標が「歩留まり」です。歩留まりを把握することで、どのフェーズに課題があり改善すべきかを明確にすることができます。
歩留まりの計算方法はシンプルで、「次の段階に進んだ人数 ÷ 前段階の人数」 で求められます。たとえば、エントリー率であれば「求人エントリー者数 ÷ 求人閲覧人数」、スカウト承諾率であれば「スカウト承諾者数 ÷ スカウト開封者数」を用いて算出します。なお、求人媒体によっては閲覧数を取得できないものや、スカウト媒体によって開封者数が計測できないケースもあります。開封者数が分からない場合は、「スカウト承諾数 ÷ スカウト送付数」を承諾率として扱うことが一般的です。
選考に関する指標
選考フェーズでは、「どの段階で辞退が多いか」「通過率が適正か」を分析します。
- 書類通過率 = 書類選考通過者数 ÷ 書類提出者数
- 面接通過率 = 面接通過者数 ÷ 面接受験者数
- 途中辞退率 = 選考途中で辞退した人数 ÷ 全受験者数
- 内定辞退率 = 内定辞退者数 ÷ 内定者数
コスト関連の指標
採用活動のROI(投資対効果)を把握するため、以下指標が役立ちます。
- 採用単価 = 総費用 ÷ 採用人数
- エージェント手数料率
期間・スピード関連の指標
選考スピードは採用競争力に直結します。リードタイムを定量的に把握することで、改善策を検討できます。 候補者のアクションに併せて細かく区切り、どこに時間がかかっているのか細かく把握しましょう。
- 応募〜書類選考案内 = 書類選考案内日 − 応募
- 書類選考案内~書類提出 = 書類提出日 − 書類案内送付日
- 書類提出~合格通知 = 合格通知日 − 書類提出日
- 合格通知~面接調整 = 面接調整完了日 − 合格通知日
- 面接調整~面接実施 = 面接実施日 − 面接調整完了日
- 面接実施~内定通知 = 内定通知日 − 面接実施日
- 内定通知~内定承諾 = 内定承諾日 − 内定通知日
入社後の活躍指標
入社後3年間の評価平均、入社後3年での離職者、などの入社後データから、「どのような人材が長期的に活躍するのか」「どの採用基準が成果につながっているのか」など、採用の「質」を定量的に検証できます。
活躍度を測る指標は企業によって異なりますが、例として次のようなデータがあります。
- 入社後3年間の評価平均(定期評価・MBO・OKRなど)
- 入社後3年以内の離職率
- 上司・同僚による360度評価
- 昇進・昇格までの期間
- 職種別の成果指標(売上・プロジェクト達成度・生産性など)
こうした分析を繰り返すことで、採用 → 配属 → 育成 → 評価 → 定着の一連のプロセスを継続的に改善できるようになります。
分析の切り口となる属性一覧
上記の指標と候補者の属性を組み合わせて分析することで、自社にマッチする候補者の特徴を検討することも可能です。例えば、応募経路ごとの書類選考通過率の差、応募月ごとの辞退率の推移、などを可視化することによって改善点を考察することができます。
- 年齢
- 経験/希望職種
- 経験/希望業界
- 応募経路
- 応募月
- 希望勤務地
採用活動のデータ分析をする上で大事な視点
「大きさ」で優先順位をつけ、「分けて」原因を特定し、「比較」で判断軸を持ち、「時系列」で効果を確認する――この4つを組み合わせることで、採用データ分析が“単なる数値の集計”から、“改善につながる分析”へ変化します。
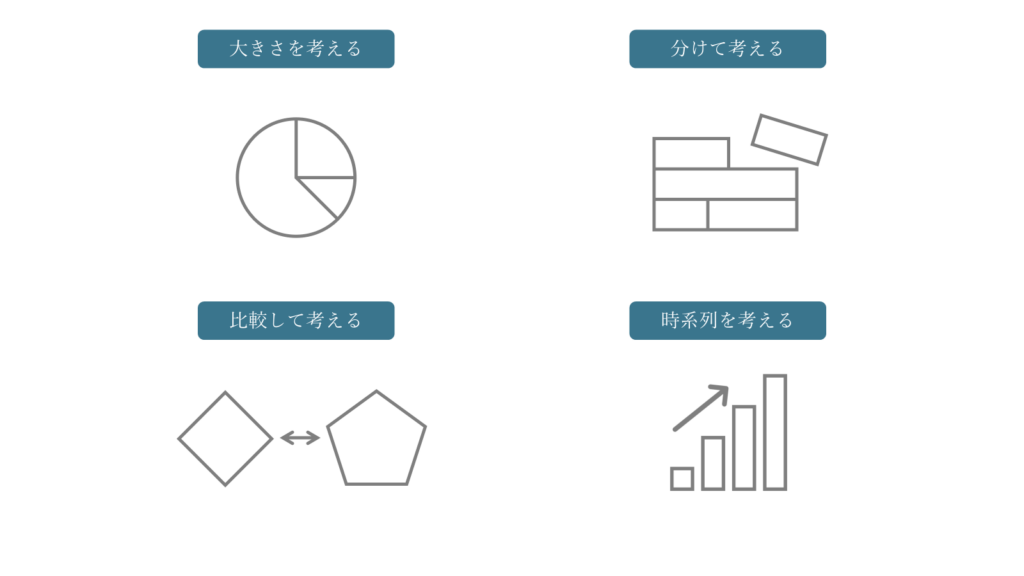
大きさを考える
採用データを分析するとき、まず重要になるのが「大きさ」の視点です。これは、どの課題が採用成果に最も大きなインパクトを与えているかを把握し、“何から手をつけるべきか” を判断するための考え方です。“どこを改善すれば採用成果が最も上がるか” を特定することで、改善の優先順位が明確になるでしょう。
分けて考える
分析の際には、意味のある切り口で分けて考えることが求められます。課題の正体を見つけるために、データを目的に沿って分解し、解像度を高めることで、初めて「どこで何が起きているのか」を正確に把握できます。
分析のポイントは、「どの切り口で(辞退・母集団形成など)」「どの工程に」「なぜ差があるのか」を意識して解像度を上げていくことです。課題の原因を曖昧なままにせず、改善策につながる具体的な材料を得ることを意識して、“分けて考える”という視点で解像度を上げていくことが欠かせません。
比較して考える
数値の「良い/悪い」を判断するには、比較軸と比較対象を明確にすることが必須です。「この比較をすることで、本当にその課題の原因が特定できるのか?」を常に問いかけ、目的に沿った適切な比較対象を設定することが求められます。
時系列を考える
単発の数値だけを見るのではなく、過去からの推移や変化の流れに注目しましょう。「現在の状況」を正しく理解するには、なぜ今その状況にあるのかを過去の経緯から知る必要があります。
【準備編】目的設定・必要データ抽出・整える
「何を」「どの順番で」「どのように」進めていくべきかを分かりやすく解説します。
目的を明確にする
データ分析の出発点は、「なぜ分析を行うのか」を明確にすることです。 目的が曖昧なままでは、どんなデータを集めればいいのか、どのように分析すればよいのかが定まりません。目的が明確になると、自然と見るべき指標や分析方法が決まってきます。たとえば「応募数を増やす」なら媒体別応募率、「辞退を減らす」ならフェーズ別辞退率が分析対象になります。
収集すべきデータを洗い出す
目的が決まったら、それを達成するために「どのデータを集めるべきか」を前述した指標一覧を参考にリストアップします。これらのデータについて、 ATS(採用管理システム)や媒体管理画面、エクセル管理表など、データの所在を明確にしておきましょう。可能であれば、すべての情報を同じエクセルやスプレッドシートなど同じファイルやシステムに収集できればベストです。
データクレンジングを行う
データを集めただけでは、正確な分析はできません。 分析前に「データの質」を整える工程=データクレンジングが欠かせません。よくある不備の例としては以下のようなものがあります。
- 同じ候補者が重複登録されている
- 未入力の項目がある
- 辞退理由がフリーテキストでバラバラ
- 日付フォーマットが統一されていない(全角/半角など)
- 空白や区切り文字があって計算に含まれていない
これらを整理・統一することで、ようやくデータ分析を行う基礎ができあがります。 クレンジング後は、決めた記載ルールを守り続け、再現性を保つことがポイントです。
【お役立ちツール】採用データ管理表excel
応募者管理用のExcelテンプレートが欲しい方は、こちらからダウンロードをどうぞ。応募受付から書類選考、面接、内定、承諾までの進捗を一つのシートで一覧管理できます。また、月別の歩留まりを可視化できるシートもご用意していますので、採用PDCAの改善にご活用ください。
【実践編】採用歩留まり分析の手順:可視化→原因特定→打ち手
採用データ分析の目的は「数字を見ること」ではなく、「原因を見つけ、実行可能な打ち手を設計して効果を検証すること」です。ここでは、実務で使える流れ(可視化 → 傾向把握 → 原因特定 → 打ち手立案・実行)を順に説明します。
実数と歩留まりを様々な切り口で整理し現状を可視化
現状のボトルネックを可視化して、どこに注力すべきかを一目でわかるようにしましょう。
① 基本となる情報を整理する
まずは費用や各選考フェーズの情報等、基本データを揃えます。
- 媒体別費用
- 応募数
- 書類提出者数/通過数
- 一次面接通過数
- 二次面接通過数
- 最終面接通過数(内定数)
- 内定承諾者数
- 入社後の評価
- 各フェーズでの辞退数
② 歩留まり(ファネル比)を計算する
フェーズごとの通過率を数値化し、どこで候補者が辞退しているかを特定します。
- 選考参加率 = 一次選考実施者数 ÷ 応募者数
- 選考通過率 = 選考通過数 ÷ 選考の実施数
- 各対応のリードタイム = 面接調整完了日 − 合格通知日など
- 途中辞退率 = 選考途中で辞退した人数 ÷ 全受験者数
- 各フェーズの辞退率 = 該当フェーズで辞退した人数 ÷ 該当フェーズの受検者数
- 内定辞退率 = 内定辞退者数 ÷ 内定数
大きさ、分ける、比較、時系列を意識して課題を特定する
影響度の大きい要素をまず見つけて、どこに課題がありそうか探しましょう。
① 大きさ(どこが最も影響が大きいかを把握する)
課題が採用成果に与えるインパクトの大きさを確認し、優先順位を決めます。
- 例:応募数の不足/通過率の低さ/辞退率の高さ など
- 例:採用単価や媒体ごとの実績を比較し、投資すべき媒体と見直す媒体を判断する
② 分ける(意味のある切り口で分解する)
データを目的に合わせて分解し、課題が発生しているポイントを特定します。
- 例:媒体別/職種別/フェーズ別(書類・一次面接・二次面接など)/辞退理由
ポイント:分析の目的を失わないことが大切です。改善策につながる材料を得るために、細かく分析しましょう。
③ 比較(基準を設けて評価する)
数値の良し悪しを判断するために、比較軸を設定
- 例:前年/先月/同業他社/施策前後/チャネル別
- 例:A/Bテスト、面接評価の比較、チャネル別応募者の質分析にも活用する
④ 時系列(変化の流れで理解する)
現状を正しく理解するために、過去〜現在の推移を把握
- 例:月別・四半期別・年度別の推移(応募数/内定率/辞退率/採用単価/選考スピード等)施策実行前後
ポイント:点で判断せず、線で検討しましょう
課題の原因を特定する
特定できた課題が起こり得る要因を幅広く洗い出し、検証によって原因を特定する
例1:職種Aの人材紹介会社経由の書類選考通過率が低い場合
- 自社内で採用要件を十分に言語化できていない
- 要件の言語化はできているが、人材紹介会社に説明する機会を十分に設けていない
- 人材紹介会社に説明はしているが、要件を正しく理解されていない
- 要件自体が高すぎて市場に該当人材が存在しないため、要件外の紹介が増えている
この場合は、人材紹介会社に実態をヒアリングし、どこで認識のズレが生じているのかを確認することで、原因を特定できます。
例2:面接官Aの2次面接実施から最終面接にかけての辞退率が高い場合
- 面接官Aによる企業理解や魅力づけが弱い
- 面接官Aによる面接での体験が候補者にとって良くない
- 他社の選考スケジュールを把握しきれておらず、選考や内定の動きが後手に回っている
この場合は、候補者一人ひとりの辞退理由を確認するとともに、面接に同席して実際の面接内容を確認することで、課題の本質が見えてきます。
例3:スカウト媒体Aでのスカウト承諾率の低さが課題である
- 媒体Aのユーザー層と、求める人物像が合っていない
- 媒体Aの企業情報に、魅力が十分に記載されていない
- 検索条件が広すぎて、アクティブ度の低い候補者やターゲット外の候補者にスカウトを送っている
この場合は、媒体担当者に媒体特性を確認することや、媒体上の企業情報・検索条件の見直しが有効です。
特定できた原因に対して改善策を実行する
分析結果に基づく改善策を実行し、効果検証まで確実に行いましょう。施策の実行前後で数値をモニタリングし、改善が見られない場合は速やかに別のアプローチへ切り替えるなど、柔軟な軌道修正が求められます。
データから異変が見えても、それが採用戦略、母集団形成、選考設計、面接官対応、候補者フォローのどこに起因しているのかは、数字だけでは判断しきれない場合があります。採用活動全体の課題を整理する考え方は、採用課題の見える化の記事で詳しく解説しています。
【ケーススタディ】目的別にみる採用データ分析の方法5選
実際にどのように進めて行くのかについて例を挙げて見ていきます
応募数を増やしたい
応募数を増やしたいと考えた時、まずは「応募数を増やす」という対策が適切なのかを判断します
- そもそも応募以外に課題があるのではないか?
→辞退率が高くないか/合格率が低くないか - 応募に問題があった場合、応募のどの段階で原因があるのか?
→求人・スカウトが見られていない/求人・スカウトを見てから応募に繋がっていない/応募・スカウトから1次選考実施までに辞退してしまっている - 求人・スカウトを見てから応募に繋がっていない場合、求人のどこに問題があるのか?
→タイトルやサムネイルの情報と求人内容が異なる/候補者視点で求人に記載しておいて欲しい情報が記載されていない/応募への経路が分かりにくい/一次選考や説明会などの入口が適切ではない
この手順で進めることで、「そもそもアプローチ先が正しいのか」「どこを直せば応募数が改善されるのか」が明確になります。
求人媒体の費用対効果を確認し、必要な対策を講じたい
求人媒体ごとにかかった費用と採用人数を以下計算式に当てはめて考えることで、採用単価を算出し、どの求人媒体が最も効率的に採用に貢献しているかを可視化します。
- 採用単価(1人採用するためにかかったコスト) = 媒体運用・利用にかかったすべてのコスト ÷ 採用人数
採用単価を比較する際、「応募単価が安い媒体」ではなく「最終的に内定につながる媒体」の見極めに着目しましょう
なるべく選考辞退者を減らしたい
辞退は「どのタイミングで」「どんな属性の人が」発生しているかをデータで把握します。
- そもそも辞退率が高いのか?
→一般的な辞退率との比較/前年同月の辞退率と比較 - どのフェーズで辞退が多いのか?
→書類選考、面接、適性検査 等 - 面接のどの段階で辞退が多いのか?
→面接案内~調整/調整~実施/実施~合否出し - 面接案内~調整で辞退が多いのはなぜか?
→調整に時間がかかりすぎている/前回選考時の対応内容に問題がある/選考案内が複雑で候補者の負担が大きい
上記以外にも、辞退理由アンケートなどの定性的な情報も合わせて分析できると理想的です。
面接官ごとの評価傾向を確認し、問題がないか確かめたい
面接官が複数いる場合だと、どうしても面接官による評価の甘辛、評価の視点に差が生まれます。誰がやっても全く同じ面接にすることは現実的に不可能ですし、ズレていること=問題とも限りません。しかし、あまりにも他の面接官と甘辛や視点が違う場合、何かしらバイアスがかかっている可能性があります。
- 面接官別の合否率・通過率
- 面接官別の各評価項目の平均点やばらつき
これらの数値を確認することで、面接官ごとに評価の傾向(評価が厳しすぎる/甘すぎる傾向や面接官ごとの評価視点の違い)が確認できます。分析結果をもとに、評価基準のすり合わせや面接官トレーニングの設計を行いましょう。
早期離職を減らし、活躍者比率を増やしたい
入社後データと採用データを突き合わせることで、「どんな採用が定着・活躍につながるか」を分析します。
- 入社後1年~3年の離職率
- 入社後評価(MBO・360度評価など)
- 採用面接時の属性データ
- 評価データ
- 採用時の適性検査(性格・志向・価値観)データ
上記のデータを組み合わせることで、
- 適性検査から見た特定の性格・志向・価値観をもった人ほど、定着率(活躍度合い)が高い
- 特定の採用時の評価軸(例:課題解決力)が高い人ほど、定着率(活躍度合い)が高い
- 特定チャネル(例:リファラル)経由者は活躍人材比率が高い
など、定着率や活躍人材比率の高さを検討することができます。
【応用編】評価傾向を掴む・活躍者を捉える・予測する
応用編では、テキストマイニングやクラスタリング、入社後データを活用した回帰分析や相関分析などの高度な手法を通じて、単なる数字の集計では見えなかった「採用の傾向や課題の本質」を明らかにします。
テキストマイニングで面接官の評価傾向を掴む
テキストマイニングとは、文章データから傾向や特徴を抽出する分析手法です。面接官の評価コメントや自由記述欄を解析することで、選考判断の偏りや重要視される評価ポイントを把握できます。
- キーワード出現頻度の分析
「主体性」「チャレンジ精神」「協調性」といった言葉の出現頻度を集計
→面接官全体で評価軸が統一されているか、偏りがないかを確認できる - 面接官ごとの評価傾向を把握
面接官Aは「コミュニケーション力」を重視する傾向が強く、面接官Bは「専門知識」をより評価する傾向がある
→ 面接官ごとの評価軸のばらつきを把握できる - コメントのポジティブ/ネガティブ傾向の可視化
評価コメントに含まれる肯定的・否定的表現を集計
→ 面接官ごとの候補者をみる視点のばらつきを把握できる
テキストマイニングは「数字に表れにくい情報」を分析できるため、面接評価の改善や面接官教育、評価基準のブラッシュアップに有効です。
適性検査のクラスタリングで活躍者のペルソナを捉える
クラスタリングとは、複数のデータを「似ているもの同士でグループ化する手法」です。適性検査の結果をクラスタリングすることで、候補者をタイプ別に分類できます。
- 配属部署との適性判断の最適化
→各クラスターの特徴と、配属を検討している部署が求める人材要件を照合し、配属先を考える上で参考にする
例:新規事業部門にはリーダータイプ、経理部門には分析タイプ - 採用面接における質問内容の個別最適化
→候補者がどのクラスターに属するかを事前に把握し、深掘りする質問や検証すべきポイントに焦点を当てた面接を実施します
例:「分析タイプ」には課題解決への思考プロセスについて質問し、思考力といった評価点をさらに引き出す
例:「リーダータイプ」にはチームで取り組んだ際の周囲との関わり方を質問し、独善的でないか懸念点を解消する - 過去の活躍社員データとの照合による採用基準の改善
例:ハイパフォーマー社員の入社前後の適性検査から特徴を抽出し、自社で活躍する可能性が高い人材の具体的なペルソナ(採用ターゲット像)を明確化
適性検査からクラスタリングすることで、ミスマッチのリスクを低減し、採用の再現性を向上させることが可能になります。
回帰分析により活躍者(離職者)を予測する
採用活動の成果は「入社者の定着率や活躍度」によって大きく左右されます。単に面接や選考通過数を追うだけではなく、入社後の活躍や離職の可能性を事前に予測できれば、より戦略的な採用が可能です。そのために有効なのが回帰分析です。回帰分析は、ある成果(例:入社後の評価、離職率)に対して影響する要因を定量的に把握する手法です。過去の入社データと選考データを組み合わせることで、「どの応募者が活躍しやすいか」「離職リスクが高いか」を予測できます。
- データを整理する
過去の入社者データ(活躍者・離職者)を集め、数値化できる項目を整理する(スコア、年数、評価点など) - 回帰モデルを作る
活躍度や離職の有無を目的変数(予測したい結果)に設定し、入社前のデータを説明変数(影響を与える要因)として分析する - モデルで予測する
新たな応募者のデータを当てはめ、活躍確率や離職リスクを予測し、高リスク者や高活躍候補者を事前に把握できる
採用活動のデータ分析を行う際の注意点とポイント
採用データを分析する際には、単に数字を集計するだけでなく、目的を明確にし、意思決定につながる分析を行うことが大切です。
定性的なデータも確認する
数字だけでは見えない課題や改善ポイントを把握するために、定性的データを活用しましょう。
- 面接官のコメントや評価メモ
- 候補者からのフィードバック(辞退理由や選考の感想)
- 社内の採用担当者からの気づきや観察記録
定性的なデータと定量データと組み合わせることで、「なぜこの結果になったか」を詳細に把握しやすくなります。
適切なサイズでPDCAを回す
データ分析は細かくやりすぎると効率が悪くなるため、分析の範囲や規模を適切に設定してPDCAを回しましょう。
- 改善の対象や規模を明確にする(例:特定の媒体や選考フェーズだけに注力)
- 小さく改善策を試し、結果を確認 → 成果が見えたら他媒体や選考フェーズへ拡大
分析と実行のバランスを意識することで、限られたリソースでも大きな効果を出しやすくなります。
分析のための分析にならないようにする
分析に熱中していると、細かいところまで分析をしすぎてしまい、目的や仮説を見失ってしまうことがあります。データ収集と考察だけで終わらせず、必ず意思決定やアクションに結びつけることを意識しましょう。
まとめ
採用データ分析は、採用活動の状態を数字で把握し、課題の発生箇所や原因を見立てるための手段です。応募数、通過率、辞退率、内定承諾率などの数値を、職種別・チャネル別・時期別・面接官別などの切り口で確認することで、感覚だけでは見えにくいボトルネックを把握しやすくなります。
一方で、データを集計しても、原因の特定や改善施策への落とし込みまで進まないケースもあります。数字だけでは判断しきれない場合は、候補者の反応、面接官の評価傾向、現場の運用状況などもあわせて確認しながら、採用プロセス全体を見直すことが求められます。
人材研究所では、採用データの整理・分析だけでなく、採用課題の特定、KPI設計、選考プロセスの改善、候補者フォローの見直しまで、企業の状況に合わせてご支援しています。採用データを見ているものの、どこから改善すべきか判断しきれない場合は、ぜひ一度ご相談ください。


曽和 利光
代表
この記事を共有する






